流处理系统本身有很多自己的特点。一般来说,由于需要支持无限数据集的处理,流处理系统一般采用一种数据驱动的处理方式。它会提前设置一些算子,然后等到数据到达后对数据进行处理。为了表达复杂的计算逻辑,包括 Flink 在内的分布式流处理引擎一般采用 DAG 图来表示整个计算逻辑,其中 DAG 图中的每一个点就代表一个基本的逻辑单元,也就是前面说的算子。由于计算逻辑被组织成有向图,数据会按照边的方向,从一些特殊的 Source 节点流入系统,然后通过网络传输、本地传输等不同的数据传输方式在算子之间进行发送和处理,最后会通过另外一些特殊的 Sink 节点将计算结果发送到某个外部系统或数据库中
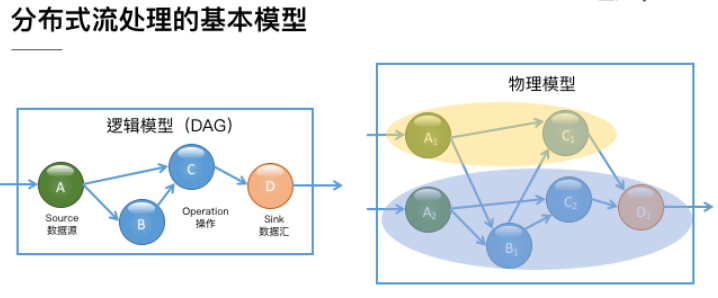
图2. 一个 DAG 计算逻辑图与实际的物理时模型。 逻辑图中的每个算子在物理图中可能有多个并发。
对于实际的分布式流处理引擎,它们的实际运行时物理模型要更复杂一些,这是由于每个算子都可能有多个实例。如图 2 所示,作为 Source 的 A 算子有两个实例,中间算子 C 也有两个实例。在逻辑模型中,A 和 B 是 C 的上游节点,而在对应的物理逻辑中,C 的所有实例和 A、B 的所有实例之间可能都存在数据交换。在物理模型中,我们会根据计算逻辑,采用系统自动优化或人为指定的方式将计算工作分布到不同的实例中。只有当算子实例分布到不同进程上时,才需要通过网络进行数据传输,而同一进程中的多个实例之间的数据传输通常是不需要通过网络的。
implementing the SourceFunction for non-parallel sources implementing the ParallelSourceFunction interface extendingtheRichParallelSourceFunctionforparallelsources.
def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment //socketFunction(env) //nonParallelSourceFunction(env) //ParallelSourceFunction(env) RichParallelSourceFunction(env) env.execute("DataStreamSourceApp") } def socketFunction(environment: StreamExecutionEnvironment): Unit ={ val data = environment.socketTextStream("localhost",9999) data.print() } def nonParallelSourceFunction(environment: StreamExecutionEnvironment): Unit ={ val data = environment.addSource(new CustomNonParallelSourceFunction).setParallelism(1)//因为实现的不是并行的SourceFunction,所以参数不能设置为2 data.print() } def ParallelSourceFunction(environment: StreamExecutionEnvironment): Unit ={ val data = environment.addSource(new CustomParallelSourceFunction).setParallelism(1)//因为实现的是并行的sourceFunction所以可以设置大于1的并行参数 data.print() } def RichParallelSourceFunction(environment: StreamExecutionEnvironment): Unit ={ val data = environment.addSource(new CustomRichParallelSourceFunction).setParallelism(1)//因为实现的是并行的sourceFunction所以可以设置大于1的并行参数 data.print() } }