什么是Flink关系型API
Flink提供了三层API。每个API在简介型和表达性之间提供了不同的权衡,并且针对不同的用例
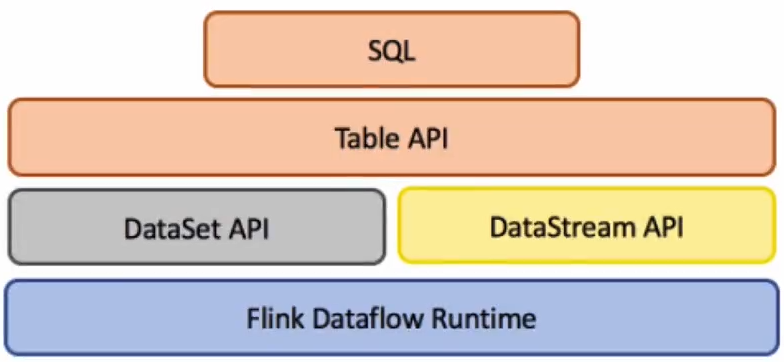
Flink具有两个关系API,即Table API和SQL。这两个API都是用于批处理和流处理的统一API,即,对无界的实时流或有界的记录流以相同的语义执行查询,并产生相同的结果。Table API和SQL利用Apache Calcite进行解析,验证和查询优化。它们可以与DataStream和DataSet API无缝集成。无论输入是批处理输入(DataSet)还是流输入(DataStream),在两个接口中指定的查询具有相同的语义并指定相同的结果。
请注意,Table API和SQL尚未完成功能,正在积极开发中。 [Table API,SQL]和[stream,batch]输入的每种组合都不支持所有操作。
Flink的关系API旨在简化数据分析,数据管道和ETL应用程序的定义。
以下示例显示了SQL查询,以会话化点击流并计算每个会话的点击次数。这与DataStream API示例中的用例相同。
1
2
3
| SELECT userId, COUNT(*)
FROM clicks
GROUP BY SESSION(clicktime, INTERVAL '30' MINUTE), userId
|
Table API & SQL特点
- 第一,Table API & SQL 是一种声明式的 API。用户只需关心做什么,不用关心怎么做,比如图中的 WordCount 例子,只需要关心按什么维度聚合,做哪种类型的聚合,不需要关心底层的实现。
第二,高性能。Table API & SQL 底层会有优化器对 query 进行优化。举个例子,假如 WordCount 的例子里写了两个 count 操作,优化器会识别并避免重复的计算,计算的时候只保留一个 count 操作,输出的时候再把相同的值输出两遍即可,以达到更好的性能。
第三,流批统一。上图例子可以发现,API 并没有区分流和批,同一套 query 可以流批复用,对业务开发来说,避免开发两套代码。
第四,标准稳定。Table API & SQL 遵循 SQL 标准,不易变动。API 比较稳定的好处是不用考虑 API 兼容性问题。
第五,易理解。语义明确,所见即所得。
1
2
3
4
5
6
7
| Table API:
tab.groupBy("word")
.select("word,count(1) as count")
SQL:
select word,count(*) AS cnt
from MyTable
group by word
|
Table API&SQL开发
WordCount示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
object TableSQLAPI{
def main(args:Array[String]):unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val tableEnv = TableEnvironment.getTableEnvironment(env)
val filePath = "file:///user/sales.csv"
import org.apache.flink.api.scala._
val csv = env.readCsvFile[SalesLog](filePath,ignoreFirstLine = true)
val salesTable = tablelEnv.fromDataSet(csv)
tableEnv.registerTable("sales",salesTable)
val resultTable = tableEnv.sqlQuery("select customerId,sum(amountPaid) money from sales group by customerId")
tableEnv.toDataset[Row](resultTable).print()
case class SalesLog(transactionId:String,customerId:String,itemId:String,
amountPaid:Double)
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
public class JavaTableSQLAPI{
public static void main(String[] args){
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEvironment();
BatchTableEnvironment tableEnv = BatchTableEnvironment.getTableEnvironment(env);
val filePath = "file:///user/sales.csv"
import org.apache.flink.api.scala._
DataSet<Sales> csv = env.readCsvFile(filePath).ignoreFirstLine().pojoType(Sales.class,transactionId,customerId,itemId,amountPaid);
Table sales = tableEnv.fromDataSet(csv);
tableEnv.registerTable("sales",sales);
Table resultTable = tableEnv.sqlQuery("select customerId,sum(amountPaid) money from sales group by customerId");
DataSet<ROw> result = tableEnv.toDataSet(resultTable,Row.class);
result.print();
}
public static class Sales{
public String transactionId;
public String customerId;
public String itemId;
public Double amountPaid;
}
}
|