前言
Hadoop 生态系统就是为处理如此大数据集而产生的一个合乎成本效益的解决方案。Hadoop 实现了一个特别的计算模型,也就是MapReduce,其可以将计算任务分割成多个处理单元然后分散到一群家用的或服务器级别的硬件机器上,从而降低成本并提供水平可伸缩性。这个计算模型的下面是一个被称为Hadoop分布式文件系统(HDFS)的分布式文件系统。这个文件系统是“可插拔的”,而且现在已经出现了几个商用的和开源的替代方案。
不过,仍然存在一个挑战,那就是用户如何从一个现有的数据基础架构转移到Hadoop上,而这个基础架构是基于传统关系型数据库和结构化查询语句(SQL)的。对于大量的SQL用户(包括专业数据库设计师和管理员,也包括那些使用SQL从数据仓库中抽取信息的临时用户)来说,这个问题又将如何解决呢?
这就是Hive 出现的原因。Hive 提供了一个被称为Hive 查询语言(简称 HiveQL或HQL)的SQL方言,来查询存储在Hadoop集群中的数据。
SQL知识分布广泛的一个原因是:它是一个可以有效地、合理地且直观地组织和使用数据的模型。即使对于经验丰富的Java开发工程师来说,将这些常见的数据运算对应到底层的MapReduce JavaAPI也是令人畏缩的。Hive可以帮助用户来做这些苦活,这样用户就可以集中精力关注于查询本身了。Hive可以将大多数的查询转换为MapReduce任务(job),进而在介绍一个令人熟悉的SQL抽象的同时,拓宽Hadoop的可扩展性。
Hive 最适合于数据仓库应用程序,使用该应用程序进行相关的静态数据分析,不需要快速响应给出结果,而且数据本身不会频繁变化。
Hive不是一个完整的数据库。Hadoop以及HDFS的设计本身约束和局限性地限制了Hive 所能胜任的工作。其中最大的限制就是Hive不支持记录级别的更新、插入或者删除操作。但是用户可以通过查询生成新表或者将查询结果导入到文件中。同时,因为Hadoop是一个面向批处理的系统,而MapReduce任务(job)的启动过程需要消耗较长的时间,所以Hive查询延时比较严重。传统数据库中在秒级别可以完成的查询,在Hive中,即使数据集相对较小,往往也需要执行更长的时间。最后需要说明的是,Hive不支持事务。
Hive是最适合数据仓库应用程序的,其可以维护海量数据,而且可以对数据进行挖掘,然后形成意见和报告等。
因为大多数的数据仓库应用程序是使用基于SQL的关系型数据库实现的,所以Hive降低了将这些应用程序移植到Hadoop上的障碍。用户如果懂得SQL,那么学习使用Hive将会很容易。如果没有Hive,那么这些用户就需要去重新学习新的语言和新的工具后才能进行生产。
同样地,相对于其他Hadoop 语言和工具来说,Hive也使得开发者将基于SQL的应用程序移植到Hadoop变得更加容易。
Hive的体系架构
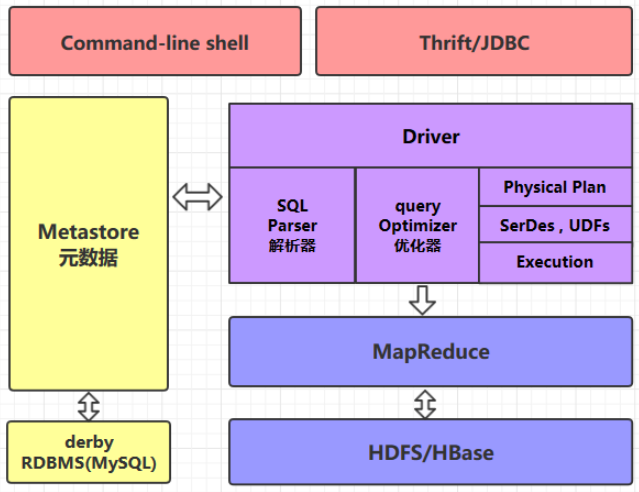
command-line shell & thrift/jdbc
可以用 command-line shell 和 thrift/jdbc 两种方式来操作数据:
- command-line shell:通过 hive 命令行的的方式来操作数据;
- thrift/jdbc:通过 thrift 协议按照标准的 JDBC 的方式操作数据。
Metastore
在 Hive 中,表名、表结构、字段名、字段类型、表的分隔符等统一被称为元数据。所有的元数据默认存储在 Hive 内置的 derby 数据库中,但由于 derby 只能有一个实例,也就是说不能有多个命令行客户端同时访问,所以在实际生产环境中,通常使用 MySQL 代替 derby。
Hive 进行的是统一的元数据管理,就是说你在 Hive 上创建了一张表,然后在 presto/impala/sparksql 中都是可以直接使用的,它们会从 Metastore 中获取统一的元数据信息,同样的你在 presto/impala/sparksql 中创建一张表,在 Hive 中也可以直接使用。
特点
简单、容易上手 (提供了类似 sql 的查询语言 hql),使得精通 sql 但是不了解 Java 编程的人也能很好地进行大数据分析;
灵活性高,可以自定义用户函数 (UDF) 和存储格式;
为超大的数据集设计的计算和存储能力,集群扩展容易;
统一的元数据管理,可与 presto/impala/sparksql 等共享数据;
执行延迟高,不适合做数据的实时处理,但适合做海量数据的离线处理。