Hive索引介绍
Hive的索引目的是提高Hive表指定列的查询速度。Hive只有有限的索引功能,但是还是可以对一些字段建立索引来加速某些操作的。一张表的索引数据存储在另外一张表中。
当逻辑分区实际上太多太细而几乎无法使用时,建立索引也就成为分区的另一个选择。建立索引可以帮助裁剪掉一张表的一些数据块,这样能够减少MapReduce的输入数据量。并非所有的查询都可以通过建立索引获得好处。通过EXPLAIN命令可以查看某个查询语句是否用到了索引。
没有索引时,类似’WHERE tab1.col1 = 10’ 的查询,Hive会加载整张表或分区,然后处理所有的rows,但是如果在字段col1上面存在索引时,那么只会加载和处理文件的一部分。
Hive 0.7.0版本中,加入了索引。
Hive 0.8.0版本中增加了bitmap索引。
Hive只有有限的索引功能。没有关系型数据库中键的概念。Hive中的索引和那些关系型数据库中的一样,需要进行仔细评估才能使用。维护索引也需要额外的存储空间,同时创建索引也需要消耗计算资源。用户需要在建立索引为查询带来的好处和因此而需要付出的代价之间做出权衡。
Hive索引机制和原理
在指定列上建立索引,会产生一张索引表(Hive的一张物理表),里面的字段包括,索引列的值、该值对应的HDFS文件路径、该值在文件中的偏移量;
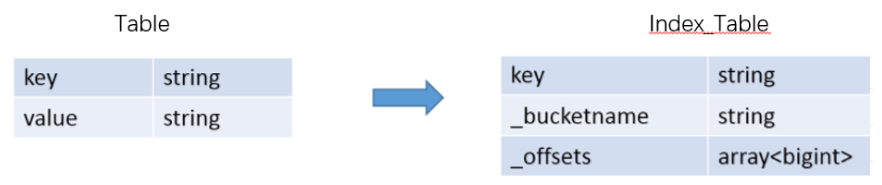
在执行索引字段查询时候,首先额外生成一个MR job,根据对索引列的过滤条件,从索引表中过滤出索引列的值对应的hdfs文件路径及偏移量,输出到hdfs上的一个文件中,然后根据这些文件中的hdfs路径和偏移量,筛选原始input文件,生成新的split,作为整个job的split,这样就达到不用全表扫描的目的。
例如:
1 | select * from t_student where name = 'zzq'; |
首先用一个job,从索引表中过滤出key = ‘zzq’的记录,将其对应的HDFS文件路径及偏移量输出到HDFS临时文件中
接下来的job中以临时文件为input,根据里面的HDFS文件路径及偏移量,生成新的split,作为查询job的map任务input
不使用索引时候,如下图所示:
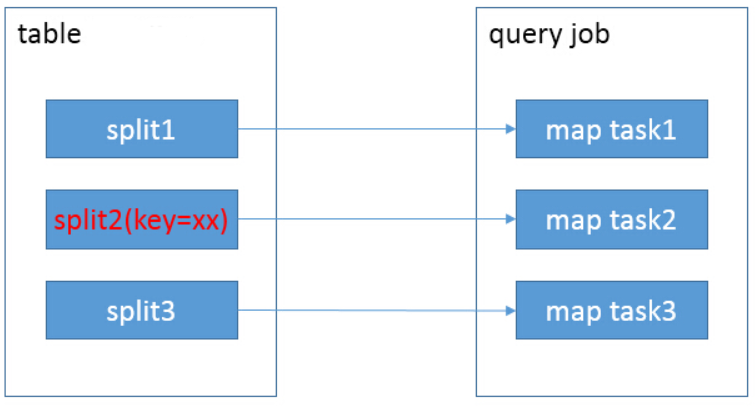
table t_student的每一个split都会用一个map task去扫描,但其实只有split2中有我们想要的结果数据,map task1和map task3造成了资源浪费。
使用索引后,如下图所示:
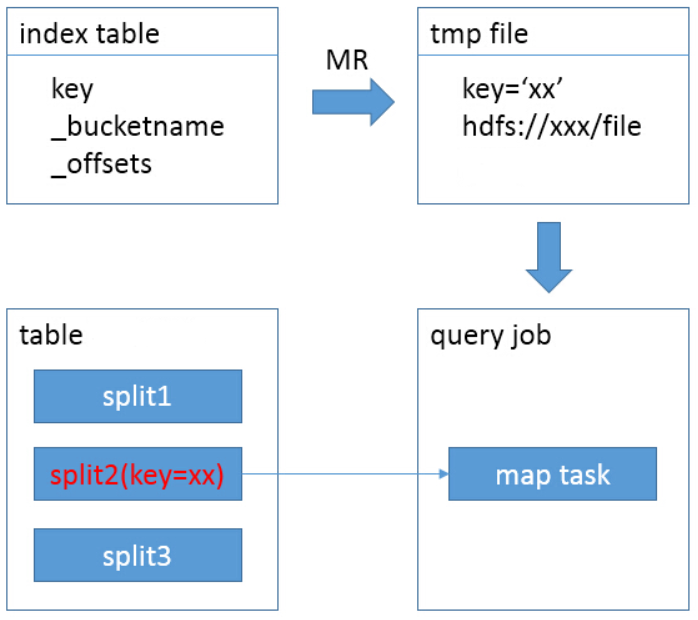
查询提交后,先用一个MR,扫描索引表,从索引表中找出key=’xx’的记录,获取到HDFS文件名和偏移量;
接下来,直接定位到该文件中的偏移量,用一个map task即可完成查询,其最终目的就是为了减少查询时候的input size
Hive索引优点
索引可以避免全表扫描和资源浪费
索引可以加快含有group by语句的查询的计算速度
创建索引表
对已有的表t_student根据name新建索引命名为student_index保存在表student_index_table中。
1 | create index student_index on table t_student(name) |
注意,创建完索引表后里面是空的,需要重建索引才会有索引的数据。
重建索引(生成索引数据)
1 | alter index student_index on t_student rebuild; |
自动使用索引
1 | SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat; |
手动使用索引
1 | SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat; |
删除索引
1 | DROP INDEX student_index on t_student; |
查看索引
1 | SHOW INDEX on t_student; |
缺点
从以上过程可以看出,Hive索引的使用过程比较繁琐:
每次查询时候都要先用一个job扫描索引表,如果索引列的值非常稀疏,那么索引表本身也会非常大;
索引表不会自动rebuild,如果表有数据新增或删除,那么必须手动rebuild索引表数据;
Hive当前的索引类型
- CompactIndexHandler(压缩索引)
- Bitmap(位图坐标)
CompactIndexHandler
通过将列中相同的值得字段进行压缩从而减小存储和加快访问时间。需要注意的是Hive创建压缩索引时会将索引数据也存储在Hive表中。对于表tb_index (id int, name string) 而言,建立索引后的索引表中默认的三列一次为索引列(id)、hdfs文件地址(_bucketname)、偏移量(offset)。特别注意,offset列类型为array。
Bitmap
位图索引作为一种常见的索引,如果索引列只有固定的几个值,那么就可以采用位图索引来加速查询。利用位图索引可以方便的进行AND/OR/XOR等各类计算,Hive0.8版本开始引入位图索引,位图索引在大数据处理方面的应用广泛,比如可以利用bitmap来计算用户留存率(索引做与运算,效率远好于join的方式)。如果Bitmap索引很稀疏,那么就需要对索引压缩以节省存储空间和加快IO。Hive的Bitmap Handler采用的是EWAH(lemire/javaewah: A compressed alternative t…)压缩方式。
案例
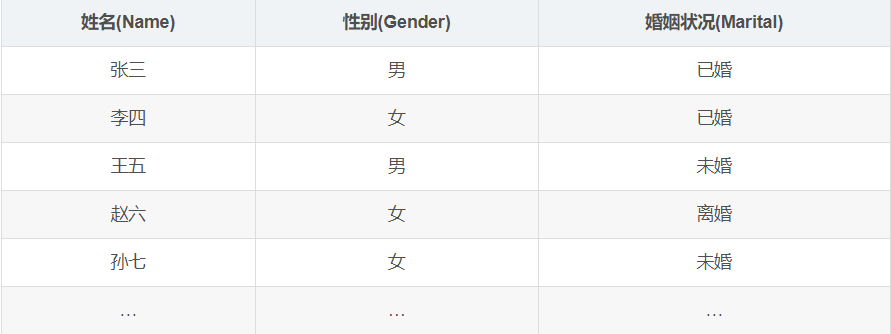
有张表名为table的表,由三列组成,分别是姓名、性别和婚姻状况,其中性别只有男和女两项,婚姻状况由已婚、未婚、离婚这三项,该表共有100w个记录。现在有这样的查询:
1 | select * from table where Gender=‘男’ and Marital=“未婚”; |
1)不使用索引
不使用索引时,数据库只能一行行扫描所有记录,然后判断该记录是否满足查询条件。
2)B树索引
对于性别,可取值的范围只有’男’,’女’,并且男和女可能各站该表的50%的数据,这时添加B树索引还是需要取出一半的数据, 因此完全没有必要。相反,如果某个字段的取值范围很广,几乎没有重复,比如身份证号,此时使用B树索引较为合适。事实上,当取出的行数据占用表中大部分的数据时,即使添加了B树索引,数据库如oracle、MySQL也不会使用B树索引,很有可能还是一行行全部扫描。
位图索引
如果用户查询的列的基数非常的小, 即只有的几个固定值,如性别、婚姻状况、行政区等等。要为这些基数值比较小的列建索引,就需要建立位图索引。
对于性别这个列,位图索引形成两个向量,男向量为10100…,向量的每一位表示该行是否是男,如果是则位1,否为0,同理,女向量位01011。
对于婚姻状况这一列,位图索引生成三个向量,已婚为11000…,未婚为00100…,离婚为00010…。
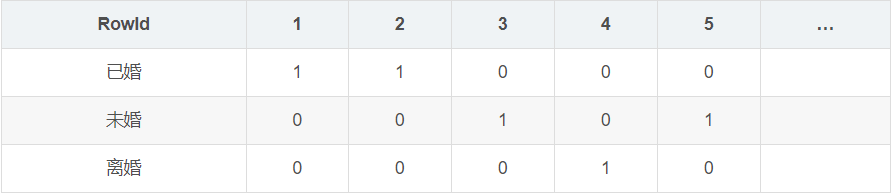
当我们使用查询语句
1 | select * from table where Gender=‘男’ and Marital=“未婚” |
的时候 首先取出男向量10100…,然后取出未婚向量00100…,将两个向量做and操作,这时生成新向量00100…,可以发现第三位为1,表示该表的第三行数据就是我们需要查询的结果。
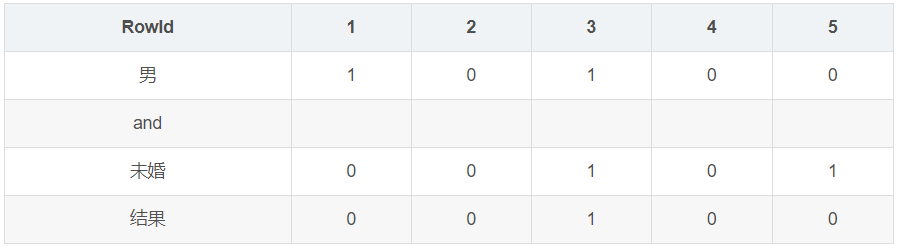
位图索引的适用条件
上面讲了,位图索引适合只有几个固定值的列,如性别、婚姻状况、行政区等等,而身份证号这种类型不适合用位图索引。
此外,位图索引适合静态数据,而不适合索引频繁更新的列。举个例子,有这样一个字段busy,记录各个机器的繁忙与否,当机器忙碌时,busy为1,当机器不忙碌时,busy为0。
这个时候有人会说使用位图索引,因为busy只有两个值。好,我们使用位图索引索引busy字段!假设用户A使用update更新某个机器的busy值,比如update table set table.busy=1 where rowid=100;,但还没有commit,而用户B也使用update更新另一个机器的busy值,update table set table.busy=1 where rowid=12; 这个时候用户B怎么也更新不了,需要等待用户A commit。
原因:用户A更新了某个机器的busy值为1,会导致所有busy为1的机器的位图向量发生改变,因此数据库会将busy=1的所有行锁定,只有commit之后才解锁。
总结
我们可以发现Hive的索引功能现在还相对较晚,提供的选项还较少。但是,索引被设计为可使用内置的可插拔的java代码来定制,用户可以扩展这个功能来满足自己的需求。 当然不是说所有的查询都会受惠于Hive索引。用户可以使用EXPLAIN语法来分析HiveQL语句是否可以使用索引来提升用户查询的性能。像RDBMS中的索引一样,需要评估索引创建的是否合理,毕竟,索引需要更多的磁盘空间,并且创建维护索引也会有一定的代价。 用户必须要权衡从索引得到的好处和代价。
参考文章