Alluxio
Alluxio(之前名为Tachyon)是世界上第一个以内存为中心的虚拟的分布式存储系统。它统一了数据访问的方式,为上层计算框架和底层存储系统构建了桥梁。 应用只需要连接Alluxio即可访问存储在底层任意存储系统中的数据。此外,Alluxio的以内存为中心的架构使得数据的访问速度能比现有方案快几个数量级。
在大数据生态系统中,Alluxio介于计算框架(如Apache Spark,Apache MapReduce,Apache HBase,Apache Hive,Apache Flink)和现有的存储系统(如Amazon S3,Google Cloud Storage, OpenStack Swift,GlusterFS,HDFS,MaprFS,Ceph,NFS,OSS)之间。 Alluxio为大数据软件栈带来了显著的性能提升。例如,百度采用Alluxio使他们数据分析流水线的吞吐量提升了30倍。 巴克莱银行使用Alluxio将他们的作业分析的耗时从小时级降到秒级。 去哪儿网基于Alluxio进行实时数据分析。 除性能外,Alluxio为新型大数据应用作用于传统存储系统的数据建立了桥梁。 用户可以以 独立集群模式,在例如 Amazon EC2, Google Compute Engine运行Alluxio, 或者用 Apache Mesos或 Apache Yarn安装Alluxio。
Alluxio与Hadoop是兼容的。现有的数据分析应用,如Spark和MapReduce程序,可以不修改代码直接在Alluxio上运行。Alluxio是一个已在多家公司部署的开源项目(Apache License 2.0)。 Alluxio是发展最快的开源大数据项目之一。自2013年4月开源以来,已有超过200个组织机构的900多贡献者参与到Alluxio的开发中。包括 阿里巴巴, Alluxio, 百度, 卡内基梅隆大学,Google,IBM,Intel, 南京大学, Red Hat,UC Berkeley和 Yahoo。Alluxio处于伯克利数据分析栈 (BDAS)的存储层,也是 Fedora发行版的一部分。 到今天为止,Alluxio已经在超过100家公司的生产中进行了部署,并且在超过1000个节点的集群上运行着。
Alluxio大数据存储系统的功能简介总结如下:
- 灵活的文件API: Alluxio的本地API类似于java.io.File类,提供了 InputStream和OutputStream的接口和对内存映射I/O的高效支持。我们推荐使用这套API以获得Alluxio的完整功能以及最佳性能。
- 兼容Hadoop HDFS的文件系统接口:基于这套接口Hadoop MapReduce和Spark可以使用Alluxio代替HDFS。
- 可插拔的底层存储: Alluxio支持将内存数据持久化到底层存储系统。Alluxio提供了通用接口以简化对接不同的底层存储系统。目前Alluxio支持Microsoft Azure Blob Store,Amazon S3,Google Cloud Storage,OpenStack Swift,GlusterFS, HDFS,MaprFS,Ceph,NFS,Alibaba OSS,Minio以及单节点本地文件系统,后续也会支持更多其他存储系统。
- Alluxio层级存储: Alluxio可以管理内存和本地存储如SSD和HDD,以加速数据访问。如果需要更细粒度的控制,分层存储功能可以用于自动化管理不同层之间的数据,确保热数据在更快的存储层上。自定义策略可以方便地应用到Alluxio,而且pin(钉住)的概念允许用户显式地控制数据的存放位置。
- 统一命名空间: Alluxio可以通过挂载功能实现不同存储系统之间的高效数据管理。并且,透明命名机制在持久化存储对象到底层存储系统时可以保留存储对象的文件名和目录层次结构。
Web UI: 用户可以通过Web UI浏览文件系统。在调试模式下,管理员还可以查看每一个文件的详细信息,包括存放位置,检查点路径等。
命令行: 用户也可以通过./bin/alluxio fs与Alluxio交互,例如:实现将数据从文件系统拷入拷出。
架构
Alluxio作为大数据和机器学习生态系统中的一个新的数据访问层,配置在任何持久性存储系统(如Amazon S3、Microsoft Azure对象存储、Apache HDFS或OpenStack Swift)和计算框架(如Apache Spark、Presto或Hadoop MapReduce)之间。请注意,Alluxio不是一个持久化存储系统。使用Alluxio作为数据访问层有如下好处:
- 对于用户应用程序和计算框架,Alluxio提供了快速存储,促进了作业之间的数据共享和局部性,而不管使用的是哪种计算引擎。因此,当数据位于本地时,Alluxio可以以内存速度提供数据;当数据位于Alluxio时,Alluxio可以以计算集群网络的速度提供数据。第一次访问数据时,只从存储系统上读取一次数据。为了得到更好的性能,Alluxio推荐部署在计算集群上。
- 对于存储系统,Alluxio弥补了大数据应用与传统存储系统之间的差距,扩大了可用的数据工作负载集。当同时挂载多个数据源时,Alluxio可以作为任意数量的不同数据源的统一层。
Alluxio可以被分为三个部分:masters、workers以及clients。一个典型的设置由一个主服务器、多个备用服务器和多个worker组成。客户端用于通过Spark或MapReduce作业、Alluxio命令行或FUSE层等应用程序与Alluxio服务器通信。
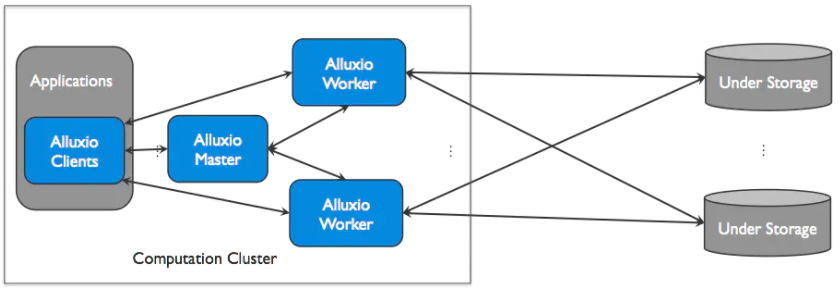
Master
Alluxio主服务可以部署为一个主master和几个备用master,以实现容错。当主master崩溃时,备用master可以被选为新的主master。
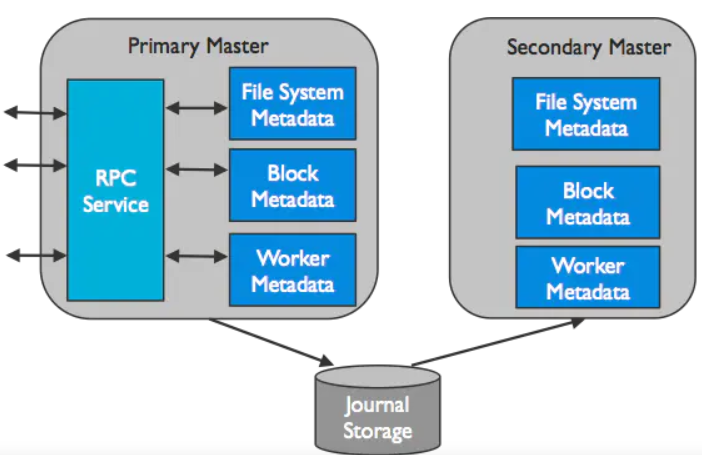
主master
Alluxio中只有一个master进程为主master。主master用于管理全局的元数据。这里面包含文件系统元数据(文件系统节点树)、数据块元数据(数据块位置)、以及worker的容量元数据(空闲或已占用空间)。Alluxio clients与主master通信用来读取或修改元数据。所有的worker都会定期的向主master发送心跳。主master会在一个分布式的持久化系统上记录所有的文件系统事务,这样可以恢复主master的信息。这组日志被称为journal。
备用master
备用master读取主master写入的journal日志,以保持与主master的状态同步。它们会对journal日志写入检查点,用于快速恢复。它们不处理来自Alluxio组件的任何请求。
Worker
Alluxio的worker用于管理用户为Alluxio定义的本地资源(内存、SSD、HDD)。Alluxio的worker将数据存储为块,并通过在其本地资源上读或者创建新的数据块来响应client请求。Workers只用于管理数据块;文件到数据块的映射存储在master中。Workers在其底层存储上进行数据操作。这带来两个重要的优势:
- 从底层存储系统读取的数据能被存储在worker中,这样别的client可以立即使用。
- client可以是轻量级的,不依赖于底层存储的连接器。
因为RAM的容量有限,所以当空间满了的时候block会被清理。Workers使用清理策略决定什么数据留在Alluxio中。 与写操作同步发生的释放空间操作将尝试根据块清理策略强制顺序删除块并释放其空间给写操作。
开箱即用的策略包括:
- LRUAnnotator:根据最近最少使用的顺序对块进行注释和释放。 这是Alluxio的默认注释策略。
- LRFUAnnotator:根据配置权重的最近最少使用和最不频繁使用的顺序对块进行注释。(如果权重完全偏设为最近最少使用,则行为将 与LRUAnnotator相同。)
参考文章